boost asio examples
Table of Contents

Asio
As far as I have tried and understand I love the Asio, it make
sense. Though I must admit I don't have full understanding of all the
nice things that asio can do, but im still learning. And as Im
learning I will try to document my findings, maybe not so much for you
to understand as it is for my self. But if anyone else finds it useful
its just a bonus. Anyhow lets start with something fun.
pipes
Since Im exploring the stream, and async_reader I got the idea of
using pipes. So lets do an initial design. I will only use one thread
for the time being. The purpose is to create a pipe and a reader
object that is basically waiting for something to appear in the
pipe and just print it out. So lets start by creating the pipes. As
for output I will be using spdlog, it has some nice features e.g to
brint hex buffers. So lets create the do the initial setup.
1: int main(int argc, char *argv[]) 2: { 3: spdlog::set_level(spdlog::level::debug); // Set global log level to spdlog::level::debug 4: auto log = spdlog::stdout_color_mt("console"); 5: 6: 7: boost::asio::io_service io_service; 8: boost::shared_ptr< boost::asio::io_service::work > work( 9: new boost::asio::io_service::work( io_service ) 10: );
So lets discuss what I've done.
- Line 4
- Create a console color log object, this will be handy to use later on, by cloning it.
- Line 7
- The
asio ioobject. - Line 10
- So that io object doesn't run out of work. Even if there aren't anything todo in queue.
Lets start from the beginning. Adding a job to the service, can be
done by calling post e.g io_service.post( job ) this will add the
job function to a queue, which when the io_service has some spare
time it will start working on. For a single threaded application all
this will be done sequentially. But some jobs might be done in
parallel, thus its possible to create a threadpool which might be used
by the io_service here is an Example. The only diffrence is that I
would probably be using lambda instead of bind, but thats just my
taste. Anyhow lets go for an example, wich might shed some light.
1: #include <iostream> 2: #include <boost/asio.hpp> 3: #include <vector> 4: #include <functional> 5: #include <thread> 6: #include "spdlog/spdlog.h" 7: #include "spdlog/sinks/stdout_color_sinks.h" 8: #include "spdlog/fmt/fmt.h" 9: #include "spdlog/fmt/ostr.h" 10: using namespace boost; 11: using namespace std::chrono_literals; 12: 13: using ThreadPoolList = std::vector< std::thread >; 14: 15: 16: ///////////////////////////////////////////////////////////////////////////// 17: // Creates a thread pool 18: // param[in] - numbers of threads in the threadpool 19: // param[in/out] - io-service to use for each of the threads. 20: // returns - a thead pool. 21: ///////////////////////////////////////////////////////////////////////////// 22: 23: ThreadPoolList createThreadPool(size_t nrThreads,asio::io_service& io_service) 24: { 25: auto& log= *spdlog::get("console"); 26: ThreadPoolList threadPool; 27: for(size_t t = 0; t < nrThreads; ++t){ 28: log.debug("Creating thread {}",t); 29: threadPool.emplace_back( [&io_service,t,&log]() 30: { 31: io_service.run(); 32: log.debug("Done! {}",t); 33: }); 34: 35: } 36: 37: return threadPool; 38: 39: } 40: 41: 42: ///////////////////////////////////////////////////////////////////////////// 43: // Creates a work 44: // param[in] - nr of jobs to executes 45: // param[in/out] - io-service to use to execute the jobs 46: ///////////////////////////////////////////////////////////////////////////// 47: 48: void createWork(size_t nrJobs,asio::io_service& io_service) 49: { 50: auto& log= *spdlog::get("console"); 51: auto mainId = std::this_thread::get_id(); 52: auto strId =fmt::format("ThreadId: {}",mainId); 53: 54: log.info("Im running the main thread {}",strId); 55: 56: for (size_t i = 0; i < nrJobs; ++i) { 57: io_service.post([&log,i,mainId]() 58: { 59: std::this_thread::sleep_for(2s); 60: auto myThreadId = std::this_thread::get_id(); 61: auto strId =fmt::format("ThreadId: {}",myThreadId); 62: log.info("Hello from {} {} {}",i,strId, 63: ((mainId == myThreadId) ? "Main" : "Other") 64: ); 65: }); 66: } 67: } 68: 69: 70: int main ( /* int argc, char* argv[]*/ ) { 71: 72: auto& log = *spdlog::stdout_color_mt("console"); 73: spdlog::set_level(spdlog::level::debug); 74: 75: asio::io_service io_service; 76: //asio::io_service::work worker(io_service); 77: 78: 79: createWork(4,io_service); 80: auto threadPool = createThreadPool(2,io_service); 81: 82: //Start running the main io_service on main thread. 83: io_service.run(); 84: 85: 86: for(std::thread& t : threadPool) { 87: t.join(); 88: } 89: 90: log.info("All done!"); 91: return EXIT_SUCCESS; 92: } 93:
Now to some explanations. The threadpool is a vector consisting of threads
. This is a convenient way of storing the threads,
Line 29 creates and inserts the thread straight into the
container, all I neeed to do is to provide the argument to what I want
to insert. Since we are using threads a lamda function is
inserted which executes run see Line 31. We know that a run
blocks until all work has finished and there are no more handlers to be
dispatched. So when we created the thread and inserted into the
threadpool, we added an call to io_service::run, this the thread
will be blocked until there is nothing else todo. We cannot decide
which thread will be used for any of the work. All we know is that
io_service will distribute the work between the threads.
If we for some reason creates the threadpool before the work, the
threadpool will just run straight through (since io_service::run
does not have any jobs). Lastly we wait for all the threads to be
finished before quitting, by calling join Line 87 on each thread.
.
Communicating
This is a broad subject, and there are numerous ways of
communicating. There are several better way of communicating than the
one that I choose (.eg dbus). But I will be using pipes, well actually I
want to use fifo files, but they are interchangable with pipes and
should be handled the same way. So lets do an example with pipes.
In this example we will be using a stream buffer supplied by boost
streambuf for more information see streambuf. I will not dwelve in
streambuffers, its an intresting topic but out of scope for this example.
Here is a link how to create streambuffers using Boost iostreams if
anyone is intrested.
Now back to the pipe example program.
1: 2: int main(/*int argc, char *argv[]*/) 3: { 4: boost::asio::io_service io; 5: std::array<int,2> pipefd; 6: 7: if( pipe(pipefd.data()) == -1 ) 8: { 9: return EXIT_FAILURE; 10: } 11: boost::asio::posix::stream_descriptor inputStream(io,pipefd[0]); 12: boost::asio::posix::stream_descriptor outputStream(io,pipefd[1]); 13:
So lets start with the first initialization phase and creating of
pipe . The following line 6 creates a pipe with 2
filedescriptors, the filedescriptors are inserted into the array and
are reffered to in the follwing way
- pipefd[0]
- is the input end of the pipe (reader)
- pipefd[1]
- is the output end of the pipe (writer)
Since Im using asio , and hope to have asyncronous write and read,
the stream_descriptor provides a stream-oriented descriptor
functionality. These are provided by boost asio for more information
see stream descriptor. Line 10 creates an input stream with
the pipe input filedescriptor and Line 11 the output part
of the pipe. We can now use the stream_descriptors to start
communicating with each other.
Lets now continue with setting up a asynchronous reader.
14: boost::asio::streambuf input_buffer; 15: boost::asio::async_read_until(inputStream, input_buffer,'\n', 16: [&input_buffer](boost::system::error_code ec, std::size_t sz) 17: { 18: std::string s( (std::istreambuf_iterator<char>(&input_buffer)), std::istreambuf_iterator<char>() ); 19: input_buffer.consume(sz); 20: std::cout << "Msg: " << s << " size " << s.size() <<" Size "<< 21: sz << " " << ec << ec.message()<< '\n'; 22: });
When something appears in our stream we need to start taking care of it, to be able to do that we need to use a buffer of some sort. This is when the stream buffer comes in handy, Line 14 uses asio to create such a buffer. More information can be found here.
Now its time to setup the actual reader part. There are several ways
of doing asyncronous reading, this example I'll be using
async_read_until, this basically reads the input of a stream until a
certain delimiter. Actually the delimiter can be a regular expression
or a funcion object that indicates a match. But for this example I
will only use a single char which is a new line char. Line 15
shows the initalization of async read, where the first argument is the
inputstream, the second is the buffer to be used, the third is the
delimiter and finally the readhandler which in this case is a lambda
expression. When something occurs on the
stream (pipe) the lambda expression will be called, with the
error_code and the size currently read. Since its asynchronous the
program want stop there, instead it will countinue.
The Line 18 is an iterator that reads the stream
buffer one character at a time until the end of the buffer,more
information can be found istreambuf_iterator link. The iterator are
passed to the constructor of a string which will create a string
based on what ever is in the buffer. When we done with the read into
the string we mark the buffer as consumed which means we can reuse
the buffer for next read.
Now to the writing part. The writing part is also going to be
asynchronous, which basically means that we provide the information to
send and then lets async_write do the magic behind. No need to stop
and wait to see that everything is transferred. That can be verified
when its all done (with help of the lamda-handler ).
23: 24: std::string out("aaaaabbbbbcccccdddddeeeee\n"); 25: //boost::asio::write(outputStream, boost::asio::buffer(out,out.size()) ); 26: 27: for(int i = 0; i < 10 ; ++i) 28: { 29: boost::asio::async_write(outputStream, 30: boost::asio::buffer(out,out.size()), 31: [](boost::system::error_code ec, std::size_t sz) 32: { 33: std::cout << "Size Written " << sz << " Ec: " 34: << ec << ec.message() << '\n'; 35: 36: } ); 37: } 38: 39: std::cout << "writing " << "\n"; 40: io.run(); 41: std::cout << "Closing " << "\n"; 42: close(pipefd[0]); 43: close(pipefd[1]);
Index sequences
Sometimes its would be nice to actually use a template variable as a number to iterate from, especially since its compile time variable.
Consider this. The goal is to use std::size_t as a variable to apply
a function N times.
e.g
1: int main() 2: { 3: auto f = [](int n) 4: { 5: std::cout << "Output: " << n << '\n'; 6: 7: }; 8: 9: applyNTimes<decltype(f),8>(f); 10: return 0; 11: } 12: 13:
So how could we do this in a compile time manner? Lets first start with the naive implementation of the interface that we call.
1: 2: template<typename J, std::size_t N> 3: applyNtimes(J job) 4: { 5: . 6: details::applyNTimes_naive<J,N>(job); 7: . 8: 9: } 10:
The naive way is to use a recursive call to e.g applyNTimes_impl
something like
1: namespace details { 2: 3: void applyNTimes_naive_impl(J j) 4: { 5: if constexpr (N == 0) 6: { 7: j(N); 8: }else 9: { 10: j(N); 11: details::applyNTimes_naive_impl<J,N-1>(j); 12: } 13: } 14: } // details 15: 16: template<typename J, std::size_t N> 17: void applyNTimes_naive(J job) 18: { 19: static_assert(N > 0 , "Nr of execution (N) needs to be > 0"); 20: details::applyNTimes_naive_impl<J,N-1>(job); 21: } 22:
This way we are applying recursively the job, one at a
time. Starting from N down to 0. As long as N > 0 line
11 will call the same function recursivly.
So what other way can we do the same? Or maybe we want to apply from 0 > N?
There is another method using index_sequence (or integer sequence, for
that matter). We start with exactly the same interface, we want to
execute a function N number of times.
We start with the interface again.
1: template<typename J, 2: std::size_t N, 3: typename Indices = std::make_index_sequence<N> 4: > 5: void applyNTimes(J job) 6: { 7: details::applyNTimes_impl<J>(job,Indices{}); 8: }
This time we actually use a default value of the third template
argument (Indices) Line 3 . Indices is of the type
std::integer_sequence and is defined as
The class template std::integer_sequence represents a compile-time sequence of integers.
Basically std::make_index_sequence creates a type (we call it
Indices) that represents a sequence of integer at compile time , we
use N as template argument to make_index_sequence to specify the
max value of our sequence (starting from 0). This
sequence can then be initialized and passed on to the implementation
of applyNTimes_impl . Lets checkout out the implementation.
1: namespace details { 2: 3: template<typename J,std::size_t... Is> 4: void applyNTimes_impl(J j, 5: std::index_sequence<Is...>) 6: { 7: (void)std::initializer_list<int>{(j(Is),0)...}; 8: } 9: 10: 11: } // details 12:
The first thing to note is the index_sequence at line
5 which is an argument of type index_sequence, but since we
don't know how long the sequence is we need to use template argument
at line 3. This defines the type index_sequence , which is a
sequence of i.e <0,1,2,3> . We can take this index sequence
execute each of the argument one at a time using initializer_list.
Actually to be more concrete and to make it simpler to understand.
lets consider this..What we want is to apply the function J the amount of times that the initializer list is defined.
j(Is)...;
Now this clearly isn't c++ code. So we need to use the
std::initializer_list, we have used it before without thinking about
it. Consider this:
auto x = {j(Is)...};
This will work except, that j is void or returning different type in
some other context. Instead we create an expression of faking a return
value.
auto x = {(j(Is),0)...};
Now the j(Is) is just a side effect and the result will be a
std::initializer_list<int> with N amount of 0 in the x
variable. The next problem is that the compiler will complain that x
is not actually used. What we want is to ignore the actual result,
this can be done using (void) but then we need to specify the actual
std::initializer_list, so we do this by applying.
(void)std::initializer_list<int>{(j(Is),0)...};
Now the return value is ignored. Well , this is all nice, but there is more.. Maybe we want to do something else too.. This is a simple example.
std::vector< int > myVect; (void)std::initializer_list<int>{ ( myVect.push_back(Is), fmt::print("Executing {} ",Is), j(Is), 0 ) ...}; fmt::print("Size of vector: {} \n",myVect.size());
In other words one can create quite complex code inside the
initializer_list.
So what are the benefits of using std::initializer_list instead of
recursive call? The code doesn't really look simpler. But are there
any other benefits.
Well, lets checkout out what the assembler language looks like.
The recursive:
.LC0: .string "Lam called " .LC1: .string "\n" main::{lambda(unsigned long)#1}::operator()(unsigned long) const: stp x29, x30, [sp, -32]! mov x29, sp str x0, [sp, 24] str x1, [sp, 16] adrp x0, .LC0 add x1, x0, :lo12:.LC0 adrp x0, _ZSt4cout add x0, x0, :lo12:_ZSt4cout bl std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) ldr x1, [sp, 16] bl std::basic_ostream<char, std::char_traits<char> >::operator<<(unsigned long) mov x2, x0 adrp x0, .LC1 add x1, x0, :lo12:.LC1 mov x0, x2 bl std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) nop ldp x29, x30, [sp], 32 ret main: stp x29, x30, [sp, -32]! mov x29, sp mov x0, 3 str x0, [sp, 24] mov w0, w1 bl void applyNTimes_naive<main::{lambda(unsigned long)#1}, 2ul>(main::{lambda(unsigned long)#1}) mov w0, 0 ldp x29, x30, [sp], 32 ret void applyNTimes_naive<main::{lambda(unsigned long)#1}, 2ul>(main::{lambda(unsigned long)#1}): stp x29, x30, [sp, -32]! mov x29, sp strb w0, [sp, 24] mov w0, w1 bl void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 2ul>(main::{lambda(unsigned long)#1}) nop ldp x29, x30, [sp], 32 ret void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 2ul>(main::{lambda(unsigned long)#1}): stp x29, x30, [sp, -48]! mov x29, sp str x19, [sp, 16] strb w0, [sp, 40] add x0, sp, 40 mov x1, 2 bl main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov w0, w19 bl void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 1ul>(main::{lambda(unsigned long)#1}) nop ldr x19, [sp, 16] ldp x29, x30, [sp], 48 ret void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 1ul>(main::{lambda(unsigned long)#1}): stp x29, x30, [sp, -48]! mov x29, sp str x19, [sp, 16] strb w0, [sp, 40] add x0, sp, 40 mov x1, 1 bl main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov w0, w19 bl void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul>(main::{lambda(unsigned long)#1}) nop ldr x19, [sp, 16] ldp x29, x30, [sp], 48 ret void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul>(main::{lambda(unsigned long)#1}): stp x29, x30, [sp, -32]! mov x29, sp strb w0, [sp, 24] add x0, sp, 24 mov x1, 0 bl main::{lambda(unsigned long)#1}::operator()(unsigned long) const nop ldp x29, x30, [sp], 32 ret __static_initialization_and_destruction_0(int, int): stp x29, x30, [sp, -32]! mov x29, sp str w0, [sp, 28] str w1, [sp, 24] ldr w0, [sp, 28] cmp w0, 1 bne .L10 ldr w1, [sp, 24] mov w0, 65535 cmp w1, w0 bne .L10 adrp x0, _ZStL8__ioinit add x0, x0, :lo12:_ZStL8__ioinit bl std::ios_base::Init::Init() [complete object constructor] adrp x0, __dso_handle add x2, x0, :lo12:__dso_handle adrp x0, _ZStL8__ioinit add x1, x0, :lo12:_ZStL8__ioinit adrp x0, _ZNSt8ios_base4InitD1Ev add x0, x0, :lo12:_ZNSt8ios_base4InitD1Ev bl __cxa_atexit .L10: nop ldp x29, x30, [sp], 32 ret _GLOBAL__sub_I_main: stp x29, x30, [sp, -16]! mov x29, sp mov w1, 65535 mov w0, 1 bl __static_initialization_and_destruction_0(int, int) ldp x29, x30, [sp], 16 ret
116 lines of code.
.LC0: .string "Lam called " .LC1: .string "\n" main::{lambda(unsigned long)#1}::operator()(unsigned long) const: push rbp mov rbp, rsp sub rsp, 16 mov QWORD PTR [rbp-8], rdi mov QWORD PTR [rbp-16], rsi mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) mov rdx, rax mov rax, QWORD PTR [rbp-16] mov rsi, rax mov rdi, rdx call std::basic_ostream<char, std::char_traits<char> >::operator<<(unsigned long) mov esi, OFFSET FLAT:.LC1 mov rdi, rax call std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) nop leave ret main: push rbp mov rbp, rsp sub rsp, 16 mov QWORD PTR [rbp-8], 3 call void applyNTimes<main::{lambda(unsigned long)#1}, 2ul, std::integer_sequence<unsigned long, 0ul, 1ul> >(main::{lambda(unsigned long)#1}) mov eax, 0 leave ret void applyNTimes<main::{lambda(unsigned long)#1}, 2ul, std::integer_sequence<unsigned long, 0ul, 1ul> >(main::{lambda(unsigned long)#1}): push rbp mov rbp, rsp call void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul, 1ul>(main::{lambda(unsigned long)#1}, std::integer_sequence<unsigned long, 0ul, 1ul>) nop pop rbp ret void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul, 1ul>(main::{lambda(unsigned long)#1}, std::integer_sequence<unsigned long, 0ul, 1ul>): push rbp mov rbp, rsp sub rsp, 32 mov esi, 0 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-8], 0 mov esi, 1 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-4], 0 lea rax, [rbp-8] mov QWORD PTR [rbp-32], rax mov QWORD PTR [rbp-24], 2 nop leave ret __static_initialization_and_destruction_0(int, int): push rbp mov rbp, rsp sub rsp, 16 mov DWORD PTR [rbp-4], edi mov DWORD PTR [rbp-8], esi cmp DWORD PTR [rbp-4], 1 jne .L8 cmp DWORD PTR [rbp-8], 65535 jne .L8 mov edi, OFFSET FLAT:_ZStL8__ioinit call std::ios_base::Init::Init() [complete object constructor] mov edx, OFFSET FLAT:__dso_handle mov esi, OFFSET FLAT:_ZStL8__ioinit mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev call __cxa_atexit .L8: nop leave ret _GLOBAL__sub_I_main: push rbp mov rbp, rsp mov esi, 65535 mov edi, 1 call __static_initialization_and_destruction_0(int, int) pop rbp ret
This has 88 lines of code.
This might not tell the complete answere but if we put N = 88 the
recursive call has
| N | Recursive | std::initializer_list |
|---|---|---|
| 2 | 116 | 99 |
| 10 | 227 | 118 |
| 88 | 1319 | 430 |
| 100 | 1487 | 478 |
As one can see the amount of assembler code is growing in a pretty
fast manner when using recursive calls, what it does is creating a new
function for every N,N-1,N-2…..0. When using initializer list it
basically just adds the execution code of the lamda and optimizes away
the std::initializer_list making it really compact in regards to the
recursive call.
This can easily bee seen if we look at the assmbler for N=10 for the
initializer code.
.LC0: .string "Lam called " .LC1: .string "\n" main::{lambda(unsigned long)#1}::operator()(unsigned long) const: push rbp mov rbp, rsp sub rsp, 16 mov QWORD PTR [rbp-8], rdi mov QWORD PTR [rbp-16], rsi mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) mov rdx, rax mov rax, QWORD PTR [rbp-16] mov rsi, rax mov rdi, rdx call std::basic_ostream<char, std::char_traits<char> >::operator<<(unsigned long) mov esi, OFFSET FLAT:.LC1 mov rdi, rax call std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*) nop leave ret main: push rbp mov rbp, rsp sub rsp, 16 mov QWORD PTR [rbp-8], 3 call void applyNTimes<main::{lambda(unsigned long)#1}, 10ul, std::integer_sequence<unsigned long, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul> >(main::{lambda(unsigned long)#1}) mov eax, 0 leave ret void applyNTimes<main::{lambda(unsigned long)#1}, 10ul, std::integer_sequence<unsigned long, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul> >(main::{lambda(unsigned long)#1}): push rbp mov rbp, rsp call void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul>(main::{lambda(unsigned long)#1}, std::integer_sequence<unsigned long, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul>) nop pop rbp ret void details::applyNTimes_impl<main::{lambda(unsigned long)#1}, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul>(main::{lambda(unsigned long)#1}, std::integer_sequence<unsigned long, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul>): push rbp mov rbp, rsp sub rsp, 64 mov esi, 0 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-48], 0 mov esi, 1 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-44], 0 mov esi, 2 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-40], 0 mov esi, 3 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-36], 0 mov esi, 4 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-32], 0 mov esi, 5 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-28], 0 mov esi, 6 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-24], 0 mov esi, 7 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-20], 0 mov esi, 8 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-16], 0 mov esi, 9 lea rdi, [rbp+16] call main::{lambda(unsigned long)#1}::operator()(unsigned long) const mov DWORD PTR [rbp-12], 0 lea rax, [rbp-48] mov QWORD PTR [rbp-64], rax mov QWORD PTR [rbp-56], 10 nop leave ret __static_initialization_and_destruction_0(int, int): push rbp mov rbp, rsp sub rsp, 16 mov DWORD PTR [rbp-4], edi mov DWORD PTR [rbp-8], esi cmp DWORD PTR [rbp-4], 1 jne .L8 cmp DWORD PTR [rbp-8], 65535 jne .L8 mov edi, OFFSET FLAT:_ZStL8__ioinit call std::ios_base::Init::Init() [complete object constructor] mov edx, OFFSET FLAT:__dso_handle mov esi, OFFSET FLAT:_ZStL8__ioinit mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev call __cxa_atexit .L8: nop leave ret _GLOBAL__sub_I_main: push rbp mov rbp, rsp mov esi, 65535 mov edi, 1 call __static_initialization_and_destruction_0(int, int) pop rbp ret
Multiple io_service
Why on earth do you want that? Well, there are circumstances.
Lets imagine that each io_service is a queue of jobs.
You can connect multiple threads to each queue. But don't let them
cross paths. That is , lets say we have 2 io_services, and lets
imagine each of them has there own thread. And each has a job of
invoke a process_job. Then its crucial that process_job is
thread-safe. But if the two io_services are completely independent,
and they never will cross paths. Lets do a small example.
The scenario here is that its a car-factory. The assembly 1 Recieves
an order, the order is performed by one of the worker. When the worker
is done he adds his part to the assembly 2 work load, one of the
worker (who ever is free) , will start working on assembling the next
part. When he is done he adds his part to the assembly 3 and when
any of the workers are done it grabs the next job.
+---------------------+ +---------------------+ +-------------------+ | +------------+ | | +------------+ | | +------------+ | | | | | | | | | | | | | | | Worker 1 | | | | Worker 1 | | | | Worker 1 | | | | | | | | | | | | | | | | | | | | | | | | | | | +------------+ | | +------------+ | | +------------+ | | | | | | | | +-----> +--> | | +------------+ | | +------------+ | | +------------+ | | | | | | | | | | | | | | | Worker 2 | | | | Worker 2 | | | | Worker 2 | | | | | | | | | | | | | | | | | | | | | | | | | | | +------------+ | | +------------+ | | +------------+ | | | | | | | | | | | | | | Assembly 1 | | Assembly 2 | | Assembly 3 | +---------------------+ +---------------------+ +-------------------+
Since we know that a io-service can attach several threads to it
lest start by making an assembly object.
Workers and Assembly Units(AU)
As we discussed earlier, each of the Assembly Units(AU) will have some
workers. Each worker can do a certain amount of work. Lets define a
worker as a thread. And the AU ass unit which takes in job into a
queue and then the first worker who is available can grab the job out
of the queue and start working on it. Fair enough, this sounds exactly
like a asio::io_context with a thread-pool attached.
This is an simple example:
1: struct Assembly 2: { 3: 4: using workerPtr = std::shared_ptr< boost::asio::io_context::work >; 5: Assembly(size_t nrWorkers) 6: { 7: onCall_ = std::make_shared< boost::asio::io_context::work >( io_ ); 8: 9: for (size_t i=0; i < nrWorkers; ++i) { 10: workers_.emplace_back( [this,i]() 11: { 12: log_->info("Worker Id: {} checked in for work",i); 13: io_.run(); 14: }); 15: } 16: 17: } 18: 19: template<typename WorkT> 20: void addWork( WorkT work) 21: { 22: io_.post( work ); 23: } 24: 25: std::shared_ptr<spdlog::logger> log_{ spdlog::get("console") }; 26: std::vector< std::thread > workers_; 27: boost::asio::io_context io_; 28: workerPtr onCall_; 29: }; 30:
This examples shows an simple implementation of an AU , lets start
with the most crucial part io_context line 27 , every AU has one. One can
think of the io_context see line 27
as a queue of jobs. The jobs are posted
into the io_context see Line 20 and when a worker aka thread is free it will grab the first
job from the queue. The worker are threads as explained before, in
this implementation the number of threads are passed in through the
nrWorkers argument and created using emplace see Line
10. Each thread is set to run see Line 13, usually this means that
when the io_context doesn't have any more work it will quite. But
since a io_context::work see Line 7 was created, this will leave the
io_context waiting. If we reset the onCall_ Line 28 and
there are no more work to be done in the io_context the threads in
the AU will be destroyed. Though, one should note that the above might
fail since we are destroying without wating for the threads to be done
with there work. So what we actually need is a destructor which
waits for the threads to be done before quitting.
Example
1: ~Assembly() 2: { 3: for( auto& th : workers_) 4: { 5: th.join(); 6: } 7: }
Now its possible to create an AU and destroy it. as this code snippet shows
1: 2: int main() 3: { 4: auto au = std::make_shared<Assembly>(3); 5: 6: au->addWork( []() 7: { 8: fmt::print("Starting to work\n"); 9: std::this_thread::sleep_for(2s); 10: fmt::print("Job done!\n"); 11: }); 12: 13: 14: au->onCall_.reset(); 15: au.reset(); 16: return 0; 17: } 18:
This examples creates a AU with 3 threads (workers) , after that it
adds one job. Since all 3 of the workers are waiting for something
todo, the first that grabs the jobs starts working. At the same time
the io_context::work object is destroyed wich means that all the
workers that don't have anything to do will run straight through and
the will be destroyed. Then the next is that the complete AU will be
destroyed. But since there is one thread still working it has to wait
being destroyed before the threads is done. After that its completely
removed.
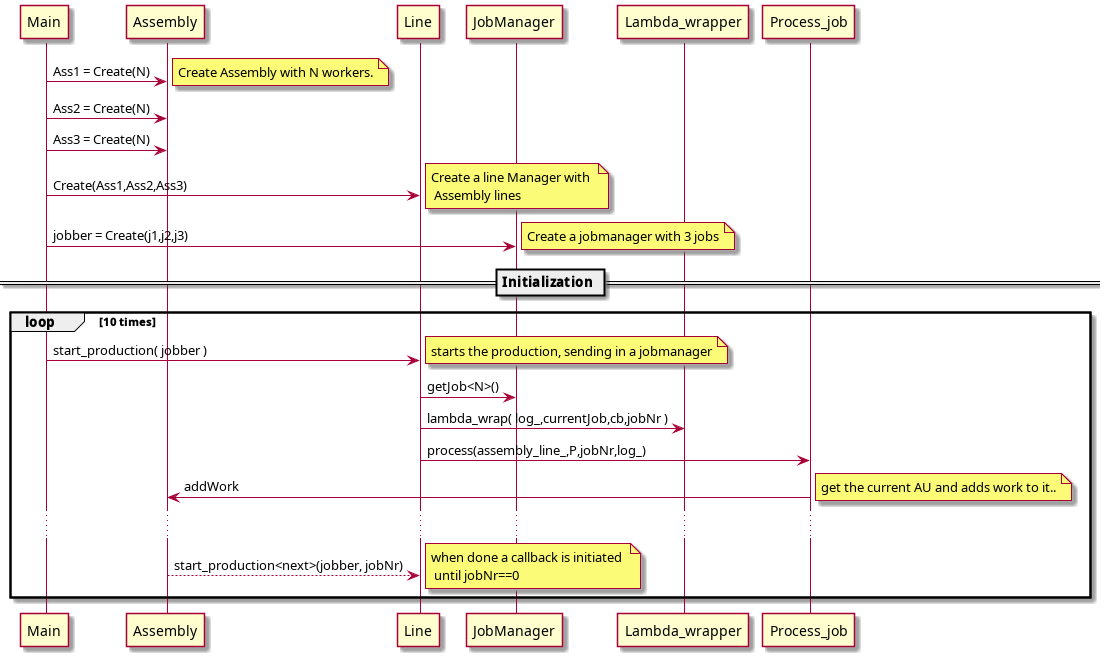
So we have our AU, we can create as many AU's we want, we can even add as many workers as we want ( not really, but anyway, in a perfect world with perfect hardware…..). But something is missing , something that knows when a job is done in one AU it should be passed to the next. In this design we need a Line manager .
Line Manager (LM)
The job for the line manager is to keep track of the AU. When the first AU is complete with its job it needs to report to the line manager that its done, the line manager can then pass along the job to the next AU and so forth until the complete production is done. This is all fare enough, but what if we want to pass in an arbitrary amount of AU's, or if there is another constellation of AU which is more effective. Somehow the Line manager needs to versatile enough to be able to cope with these issues.
Arbitrary amount of AU's
With the new c++11 a wonderful feature called variadic templates was introduced. This basically means that we can have an arbitrary amount of template argument to our functions or structs in a type-safe way, and have all the argument handling logic resolved in at compile-time.
1: template<typename... Args> 2: void do_something(Args... args) 3: { 4: //Do something useful 5: }
This means we can any number arguments with any number of types to the
function do_something. This is exactly what we want! We want to
specify how many AU's we want to use. But we don't want to change the
LM everytime we want to change something. So lets define it this way.
1: 2: template< typename... Stations> 3: struct Line 4: { 5:
The argument Stations is variadic since it doesnt specify how many
it is. On the other hand, it needs to be specified at compile
time. Meaning we cannot change it with for example, program arguments.
But in this design we know how many AU's we will be using for our
production, so its not an issue.
But we need to store all the AU's someway. There are of course
several ways of doing this. But since we are looking for an versatile
design the Stations can be of many different types. Lets imagine we
find a better way of doing the work for some special AU. We could of
course created a interface, and implemented inheritance, then we
wouldn't have needed the variadic templates but on the other hand ,
that would have caused alot of runtime overhead. The interface on the
other hand could have been used if we want to change the amount of
AU's during runtime. But thats not what we want, so we are stuck with
the variadic templats.
Storing types
The first thing that comes to ones mind when talking about different
types is of course std::variants , but to be honest, i find
std::variants to be a pain in the ass. It sure has its benefits and
it sure has many useful places it can be used. But for this design,
I'm not convinced. How about std::vector or any other container?
Well, then we need an interface, and pointers and container aso…..
Nop, not my choice. Tuples, on the other hand! A tuple is like a list
of types, its perfect, it only has one little caveats, it needs to be
defined at compile time..Well, thats not a problem for us. We just
said we know how many AU's we will use at compile time.
Class template std::tuple is a fixed-size collection of heterogeneous values.
Well, thats it! cppreference on tuples.
So we take all the Stations and add them to a tuple
1: 2: template< typename... Stations> 3: struct Line 4: { 5: 6: 7: Line( Stations... sts): 8: assembly_line_(std::make_tuple(sts...)) 9: { 10: 11: } 12: 13: . 14: . 15: . 16: /*!< Assembly line with different assembly units */ 17: std::tuple<Stations...> assembly_line_; 18: };
This is the constructor creating a tuple of AU's see Line
7 and adds them to the struct variable assembly_line_
Line 16 to notice here is that we can actually use the
variadic template argument Stations to be the type to the tuple.
So we manage to create a list of Assembly unit even if there not the
same type. So we need to add some job to the Line manager.
So lets define a method that does that. I will keep this simple to start with, all the AU's will do the same job. So we need a method that adds a job.
Add a job
In this implementation all the AU's will perform the same job, this to keep it simple and understandable. Lets define the method as.
1: template< typename... Stations> 2: struct Line 3: { 4: . 5: . 6: . 7: 8: template<typename JobT> 9: void start_production(JobT const& job) 10: { 11: constexpr auto nrAu = std::tuple_size<decltype(assembly_line_)>::value; 12: start_production_impl<JobT,nrAu-1>(job); 13: ++job_nr_; 14: } 15: . 16: . 17: int job_nr_; 18: };
To keep track on what job has been in what AU we add a
job_nr Line 17. Its a simple int, and after we start a
production on a job, we just increase that number. We also need to
know the tuple size, that is how many AU's is contained in the
tuple. Fortunatly the std::tuple_size is part of the standard for
more information see tuple_size on cppreference. To quote cppreference:
Provides access to the number of elements in a tuple as a compile-time constant expression.
That means we can obtain the number of elements in the tuple at
compile time Line 11. This number can then be used to iterate through the AU's
in the tuple, when one is done we can move on to the next, until the
job is finally finished and the coolest thing is that we let the
compiler do the iteration since the iteration is on compile time.
Though as mentioned before all template
arguments needs to be there at compile time. But thats not a problem
since thats exactly what tuple_size does. One little problem is that
tuple_size needs to know the type of the tuple, so we need to use
decltype to get the actual type for the assembly_line_ to be able to
get to the size. The next thing to do is to actual call the
production implementation, which takes two template arguments, one for
the job and one which AU's to use. Since the size shows the number of
elements in the assembly line, we actually want the index of the first
AU, thats why we decrease the size by 1 when calling implementation
see Line 12, we also need to provide the job which the AU
needs to be doing.
Production Implementation
As mentioned before the implementation is a template function, which iterates through the job. It will be compile-time recursive, that means the recursion will be done during compile time. Well actually as I understood it the functions with the specific template arguments will be inserted into the code as functions. Lets consider this really simple program.
1: #include <functional> 2: 3: template< std::size_t N> 4: void do_something() 5: { 6: int x=1; 7: if constexpr( N == 0 ) 8: return; 9: else 10: do_something<N-1>(); 11: } 12: 13: int main() 14: { 15: constexpr int i = 3; 16: do_something<i>(); 17: 18: return 0; 19: 20: }
If we use cppinsight.io and paste that code, and compile it. We get:
1: #include <functional> 2: 3: 4: template< std::size_t N> 5: void do_something() 6: { 7: int x=1; 8: if constexpr( N == 0 ) 9: return; 10: else 11: do_something<N-1>(); 12: } 13: 14: /* First instantiated from: insights.cpp:19 */ 15: #ifdef INSIGHTS_USE_TEMPLATE 16: template<> 17: void do_something<3>() 18: { 19: int x = 1; 20: if constexpr(3ul == 0) ; 21: else /* constexpr */ do_something<3ul - 1>(); 22: 23: 24: } 25: #endif 26: 27: 28: /* First instantiated from: insights.cpp:11 */ 29: #ifdef INSIGHTS_USE_TEMPLATE 30: template<> 31: void do_something<2>() 32: { 33: int x = 1; 34: if constexpr(2ul == 0) ; 35: else /* constexpr */ do_something<2ul - 1>(); 36: 37: 38: } 39: #endif 40: 41: 42: /* First instantiated from: insights.cpp:11 */ 43: #ifdef INSIGHTS_USE_TEMPLATE 44: template<> 45: void do_something<1>() 46: { 47: int x = 1; 48: if constexpr(1ul == 0) ; 49: else /* constexpr */ do_something<1ul - 1>(); 50: 51: 52: } 53: #endif 54: 55: 56: /* First instantiated from: insights.cpp:11 */ 57: #ifdef INSIGHTS_USE_TEMPLATE 58: template<> 59: void do_something<0>() 60: { 61: int x = 1; 62: if constexpr(0ul == 0) return; 63: 64: 65: } 66: #endif 67: 68: 69: 70: 71: int main() 72: { 73: constexpr const int i = 3; 74: do_something<i>(); 75: return 0; 76: }
Here we can see that the do_something function will actually be part
of the code 4 times, as template specialization since the compiler
knows that we will use it four times. This is the only time I will be
using assembler, but to see the assembler might shed even more light
on what I mean.
1: main: 2: push rbp 3: mov rbp, rsp 4: sub rsp, 16 5: mov DWORD PTR [rbp-4], 3 6: call void do_something<3ul>() 7: mov eax, 0 8: leave 9: ret 10: void do_something<3ul>(): 11: push rbp 12: mov rbp, rsp 13: sub rsp, 16 14: mov DWORD PTR [rbp-4], 1 15: call void do_something<2ul>() 16: nop 17: leave 18: ret 19: void do_something<2ul>(): 20: push rbp 21: mov rbp, rsp 22: sub rsp, 16 23: mov DWORD PTR [rbp-4], 1 24: call void do_something<1ul>() 25: nop 26: leave 27: ret 28: void do_something<1ul>(): 29: push rbp 30: mov rbp, rsp 31: sub rsp, 16 32: mov DWORD PTR [rbp-4], 1 33: call void do_something<0ul>() 34: nop 35: leave 36: ret 37: void do_something<0ul>(): 38: push rbp 39: mov rbp, rsp 40: mov DWORD PTR [rbp-4], 1 41: nop 42: pop rbp 43: ret
Here we see the assembler output and can straight away see that
do_something is actually four functions, one for each of the
template argument. If we for example forget the if constexpr(N == 0)
expression, then the compiler would need to do std::size number of
functions, which will make the compilation to crash.
- Line 6
- The first initial call to
do_something<3>() - Line 10
do_somethingWhen N == 3- Line 19
do_somethingWhen N == 2- Line 28
do_somethingWhen N == 1- Line 37
do_somethingWhen N == 0
This is exactly the same thing we will do with the
start_production_impl, but with some extra salt on it.
So lets smack it right in there and try to disect it.
1: template< typename... Stations> 2: struct Line 3: { 4: . 5: . 6: . 7: . 8: . 9: 10: template<typename JobT,std::size_t N> 11: void start_production_impl(JobT const& job, int jobNr) 12: { 13: constexpr auto next = N-1; 14: auto cb = [=]() 15: { 16: 17: if constexpr (N > 0 ) 18: { 19: log_->debug("Next AU <{}>",next); 20: start_production_impl<decltype(job),next>(job,jobNr); 21: } 22: }; 23: 24: auto F = details::Lamda_wrapper<N>::lambda_wrap(log_); 25: auto P =F(job,job_nr_,cb); 26: 27: details::Process_job< decltype(assembly_line_), decltype(P), N>:: 28: process(assembly_line_,P,jobNr,log_); 29: 30: } 31: 32: . 33: . 34: . 35: . 36: };
Lets start at the top, the template argument JobT is the type of the
job that the AU's are to do. The N is the current AU number, for
this implementation the first AU has the highest number, not really
intuitive but we just want to keep the code as simple as possible.
A job is considered to be a functor.
Functors are objects that can be treated as though they are a function or function pointer.
For this example lets consider the job to be a lambda expression of
some sort, no need to dwelve into to much details. The next variable
which is defined on Line 13, is the next AU in line, meaning
when we done with the current AU, we should use the next which is
\[next = current-1\]
The line manager must know when to pass the current job from the
current AU to the next AU. Lets say current AU is 2, then the next AU
will be one, but the line manager is not allowed to send the job
before the AU[2] is completely done. So somehow he needs to be
notified that the work is done from an AU, what better way to do that
then let the worker tell him that the job is done by a callback,
Line 14. This is a lamda expression using capture by copy.
We also see that this callback checks if the next AU is N == 0 in
that case it should not do anything. But in any other case it should
call recursivly start_production_impl with the next AU number and
the job. So we have the callback covered. What next.
Well, to be able to use the callback, we need somehow to wrap the job lambda and the callback lambda into a new lambda. See next section for this.
Lambda wrapper
The problem with the wrapper is that we need to provide the lamda
function with values that are current. Consider the fact that we need
to provide the right callback functor with the right AU number, I
also want the line manager log together with some output for
readability. So lets dive into the code.
1: template< std::size_t N> 2: struct Lamda_wrapper 3: { 4: static auto lambda_wrap(Logger log) 5: { 6: 7: return [=](auto const fun_org,int job_nr,auto cb) 8: { 9: 10: 11: return [=]() 12: { 13: log->debug("AU<{}> working on Job [{}]", N, job_nr ); 14: fun_org(); 15: cb(); 16: log->info("AU<{}> done! [{}]",N,job_nr); 17: }; 18: }; 19: }; 20: }; 21:
No need to be intimidated, its not as bad as it looks. So whats the
deal? Well, the job function needs to be a functor, but the problem is
that we want to provide some additional information. In this case its
log and a callback function together with the original job functor
and not the least the current AU number which can be found Line 1.
To be able to do that I've created a template function, which returns
a lamda function, but this one needs argument Line 7
lets call this the outer. When those arguments are provided, the
function will return a new lambda , which has captured all the necessary
information that was provided by the outer lambda. In this case we get
a new function which is a functor and can be called without any
arguments. This is exactly what the following two lines does.
1: auto F = details::Lamda_wrapper<N>::lambda_wrap(log_); 2: auto P =F(job,job_nr_,cb);
The first calls lambda_wrap with log arguments will return the outer
lambda functor. But this functor needs arguments, so we provide it
with the necessary information, by doing that we will recive a
functor which can be called ecplicitly with no arguments. Exactly as
we want it. We have now modified the original lambda job and provided
logs and a callback. We are now ready to proceed by calling the actual
AU and give it our new job. Ok one might wonder why in earth do we
need 2 lambdas? Good question and the reason is that auto is not
allowed in function prototype, though it is allowed in lambdas. Though
one could have passsed it as template arguments. I.e
1: template< std::size_t N, typename JobT, typename CbT> 2: struct Lamda_wrapper 3: { 4: static auto lambda_wrap(Logger log, JobT fun_org, CbT cb, int job_nr) 5: { 6: 7: return [=]() 8: { 9: log->debug("AU<{}> working on Job [{}]", N, job_nr ); 10: fun_org(); 11: cb(); 12: log->info("AU<{}> done! [{}]",N,job_nr); 13: 14: }; 15: }; 16: };
Maybe easier to read but the call to the lambda wrap would be.
1: auto P = details::Lamda_wrapper<N,JobT,decltype(cb)>::lambda_wrap(log_,job,cb,job_nr_);
I don't know , its up to the reader what you prefer, I don't see any difference in the two ways. Lets move on, the next part is to actually call the workers with our ned lambda. There is one other thing that I hanven't mentioned that needs to be considered. But I leave this to later in a broader discussion.
Pass job
to actually retrieve a value/object from a tuple we must use std::get<N>(tuple)
the problem with get is that N needs to be known at compile
time. I.e
1: auto tupp = std::make_tuple("hello",1,2,3.14); 2: constexpr auto index = 3; 3: std::cout << "Hi: " << std::get<0>(tupp) << " What pi: " << std::get<index>(tupp) << '\n'; //Works fine! 4: int x = 2; 5: std::cout << std::get<x>(tupp) << '\n'; //ERROR!! x is not compile time defined.
As long as index is compile time defined it works fine. So this means we need to pass the N along to the process function.
So how does the process job look like. its fairly simple:
1: ///////////////////////////////////////////////////////////////////////////// 2: // Process_job - get the right tuple from the assembly and executes the jobid 3: ///////////////////////////////////////////////////////////////////////////// 4: template<typename Tuple,typename JobT,std::size_t N> 5: struct Process_job 6: { 7: static void process(const Tuple& tp, const JobT& job , int jobId, Logger log) 8: { 9: auto current_assembly = std::get<N>(tp); 10: log->debug("Process job {} current AU <{}>",jobId,N); 11: current_assembly->log_->debug("Im Worker"); 12: current_assembly->addWork(job); 13: } 14: };
The process_job needs of course the assmembly line. Fair and square, it
retrieves the current AU from the assembly unit Line 9.
And then adds the modified job (see Production implementation) .
The assembly unit will add the job to its queue Line 12 and
Voila! When the AU is done a callback will be executed through our
modified function if the there is still AU's to be done then a new
call pro process , and a new callback until N=0..
Thread safty
Is there any issues with this implementation? Yes, the callback!
The start_production_impl is called from the callback, and every
time it is called from a different thread. So is it thread safe?
Maybe, im not really sure anymore. But when im not sure lets make it
safe instead. By letting the callback post a job from one thread to
the manager io context we make sure that whenever the linemanager has
time to process the job, it will do it. The job is still done by the
Assembly unit though through the Process_job. We also need to add
an post from start_production call, to make sure that this is also
included in the thread safty procedure. Here is the new thread safe
version of program.
1: template<typename JobT> 2: void start_production(JobT const& job) 3: { 4: //constexpr auto nrAu = get_nr_AUs(); 5: constexpr auto nrAu = std::tuple_size<decltype(assembly_line_)>::value; 6: io_.post([=]() 7: { 8: start_production_impl<JobT,nrAu-1>(job,job_nr_); 9: ++job_nr_; 10: log_->debug("Main is using {}", details::thread_str()); 11: }); 12: 13: 14: 15: 16: 17: } 18: 19: 20: 21: 22: template<typename JobT,std::size_t N> 23: void start_production_impl(JobT const& job, int jobNr) 24: { 25: //auto jobId = job_nr_; 26: constexpr auto next = N-1; 27: auto cb = [=]() 28: { 29: 30: log_->debug( "Callback is called from thread {}",details::thread_str()); 31: 32: io_.post([=]() 33: { 34: if constexpr (N > 0 ) 35: { 36: log_->debug("Next AU <{}> Current Thread {}",next,details::thread_str()); 37: start_production_impl<decltype(job),next>(job,jobNr); 38: }else 39: { 40: log_->info("Production Done for job[{}] Current thread: {}",jobNr,details::thread_str()); 41: } 42: 43: }); 44: 45: }; 46: 47: auto P = details::Lamda_wrapper<N,JobT,decltype(cb)>::lambda_wrap(log_,job,cb,jobNr); 48: // auto F = details::Lamda_wrapper<N>::lambda_wrap(log_); 49: // auto P =F(job,job_nr_,cb); 50: 51: details::Process_job< decltype(assembly_line_), decltype(P), N>:: 52: process(assembly_line_,P,jobNr,log_); 53: 54: }
Jobs jobs and jobs
Well, until now the jobs has been the same for every AU. In this part I will try to change that so that every AU has its own job-function(JF) to work with. The principle is simple a job is associated with a AU, when production the job is sent to the right AU.
Production